
AWS「S3」にあるCSVファイルを基に「Athena」でテーブルを作成して、SQLクエリを発行します。
CSVファイルを用意する
CSVファイルをS3バケットにアップロードします。 動作確認用のデータとして、タイタニックデータセット(Titanic dataset)を使ってみます。タイタニックデータセットは「1912年に北大西洋で氷山に衝突して沈没したタイタニック号への乗客者の生存状況」のデータセットです。
タイタニックデータセットを下記のURLの「Download All」より「titanic.zip」ファイルをダウンロードし、解凍します。
https://www.kaggle.com/c/titanic/data
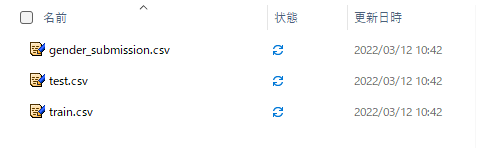
ZIPファイルを解凍すると「gender_submission.csv」「test.csv」「train.csv」の3つのファイルが入っていることを確認できます。今回は学習用データの「train.csv」をS3にアップロードします。
AWS S3バケットにCSVファイルをアップロードする
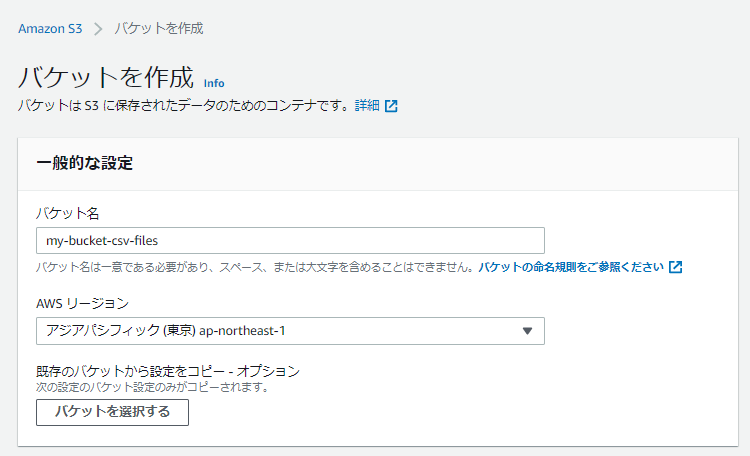
AWS S3にアクセスし、「バケットを作成」をクリックします。
![]()
バケット名を入力し、「バケットを作成」をクリックします。
![]()
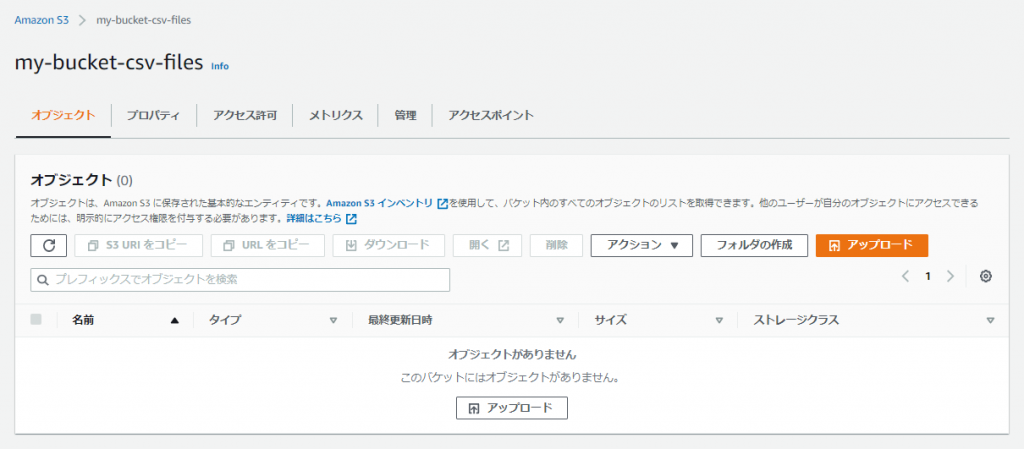
作成したバケットの画面で「アップロード」ボタンをクリックします。
アップロード画面の「ファイルを追加」ボタンをクリックし、タイタニックデータセットの「train.csv」をクリックします。
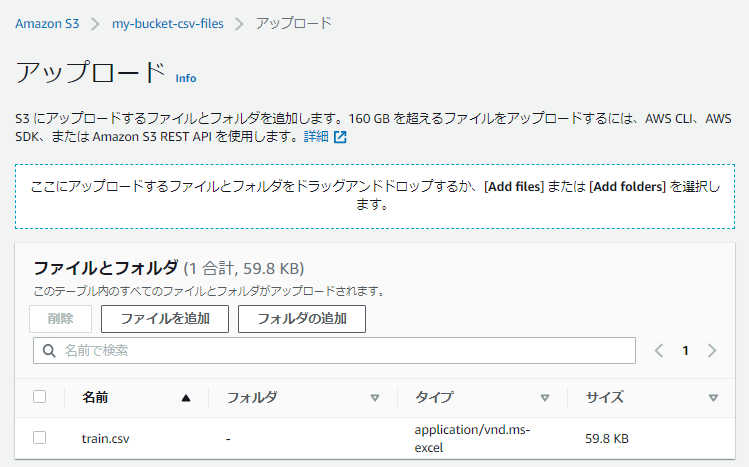
「train.csv」がアップロードリストに表示されたら、「アップロードボタン」をクリックします。

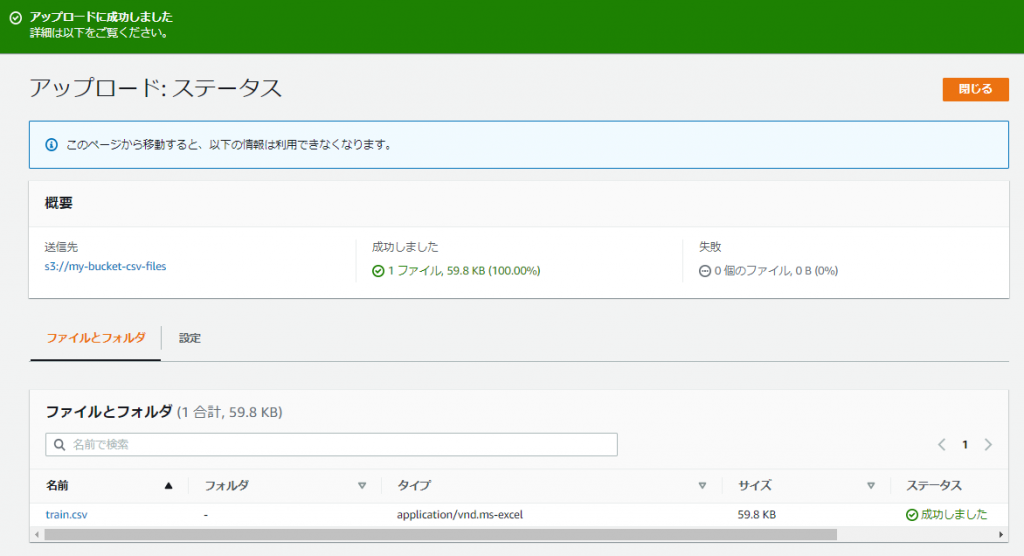
アップロード:ステータス画面になり、ステータスが「成功しました」になっていればアップロードは成功です。「閉じる」ボタンをクリックします。
AWS Athenaで
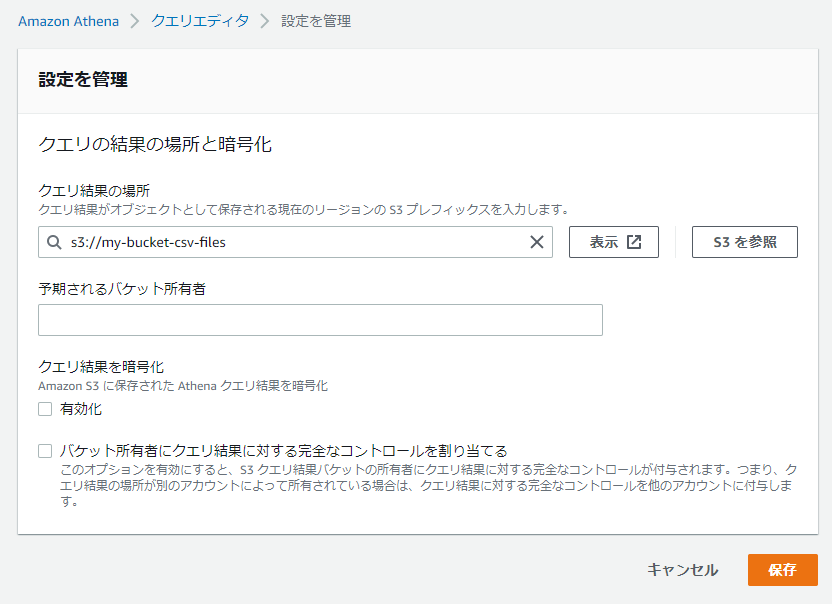
「Athena」でテーブルを作成しますが、前準備としてクエリの結果の場所を設定しておきます。
「設定」画面(Athena > クエリエディタ > 設定 )で、「S3を参照」よりクエリ結果の保存先のバケットを選択し、「保存」ボタンをクリックします。
「エディタ」画面(Athena > クエリエディタ)のテーブルとビューの「作成」>「S3バケットデータ」を選択します。
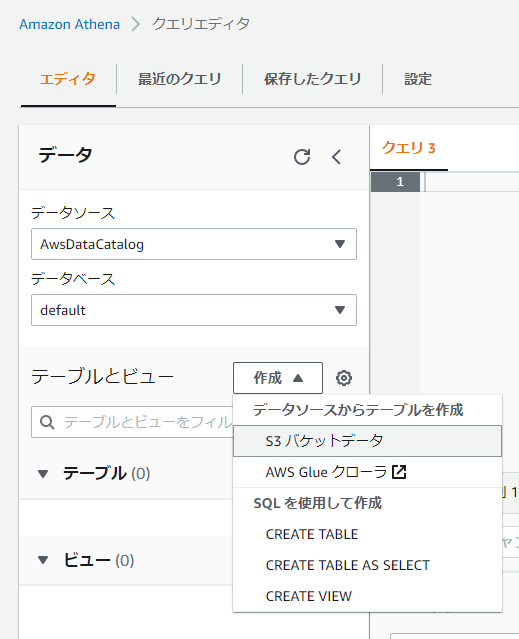
「S3バケットデータからテーブルを作成」画面が表示されましたら、「テーブル名」を入力します。
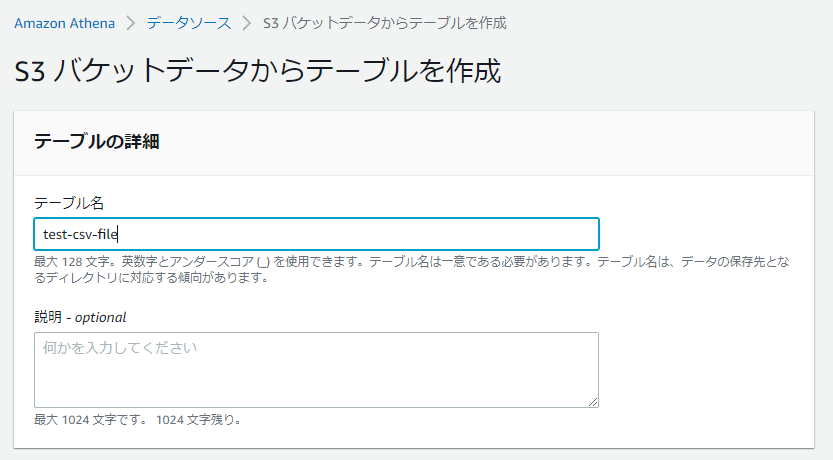
「データベース設定」で”データベースを作成”をクリックします。
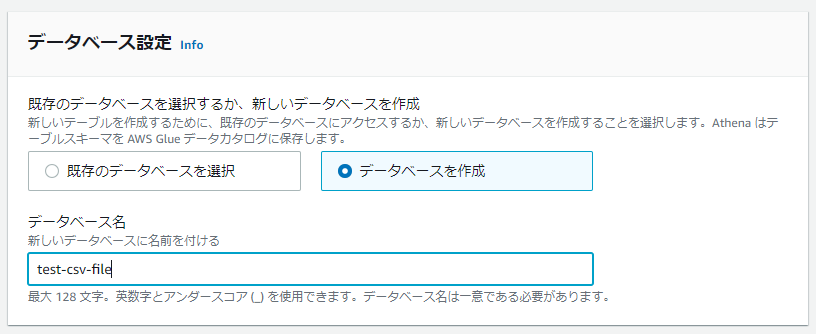
「データセット」を「S3を参照」ボタンより参照します。
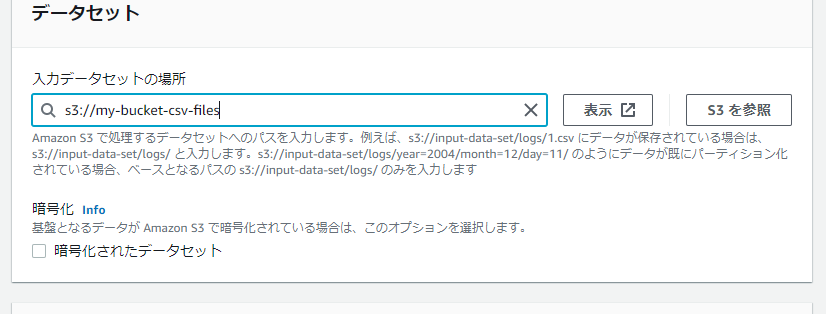
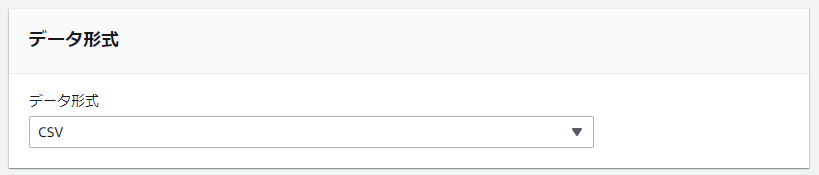
「データ形式」で”CSV”を選択します。
「列の詳細」でCSVファイル(train.csv)の各列のデータの”列名”と”列のタイプ”を設定します。
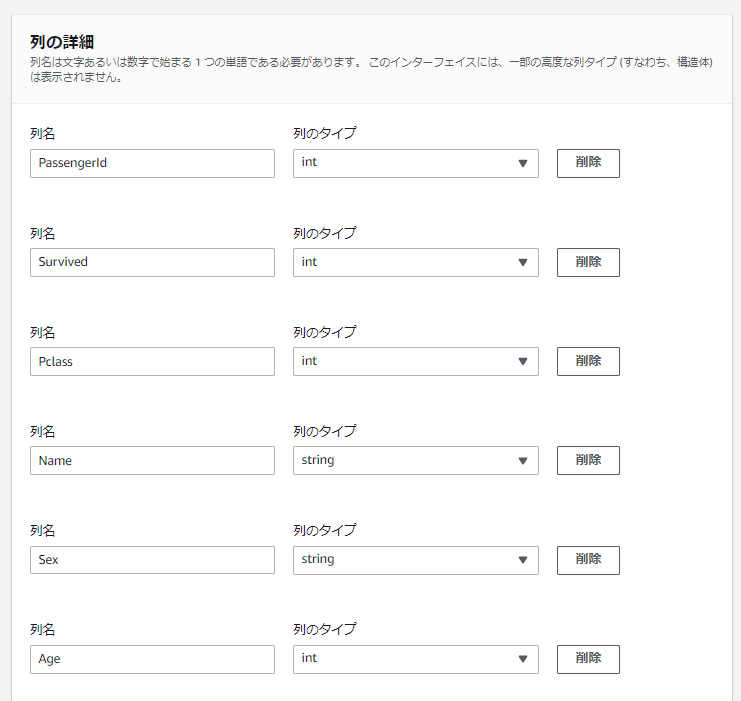
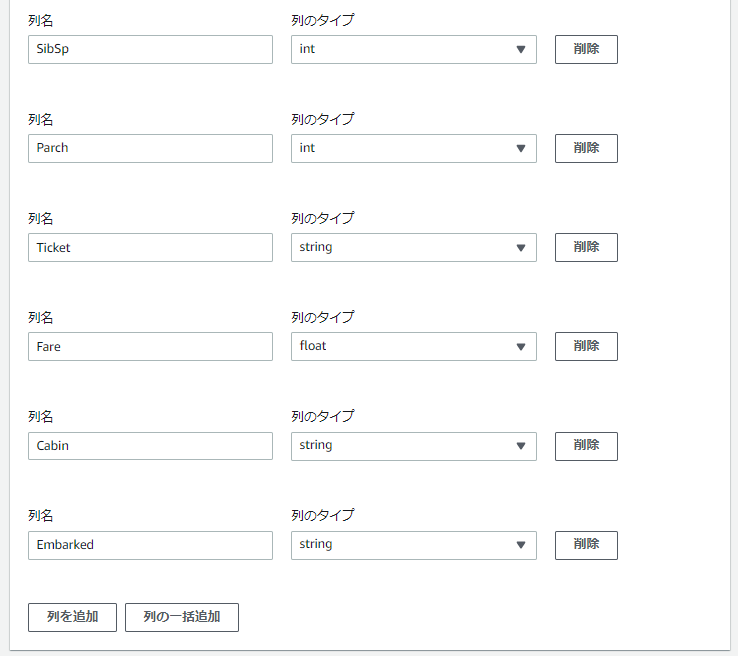
「テーブルを作成」ボタンをクリックします。

「エディタ」画面に戻るので、データベースを選択し、「実行」ボタンをクリックします。
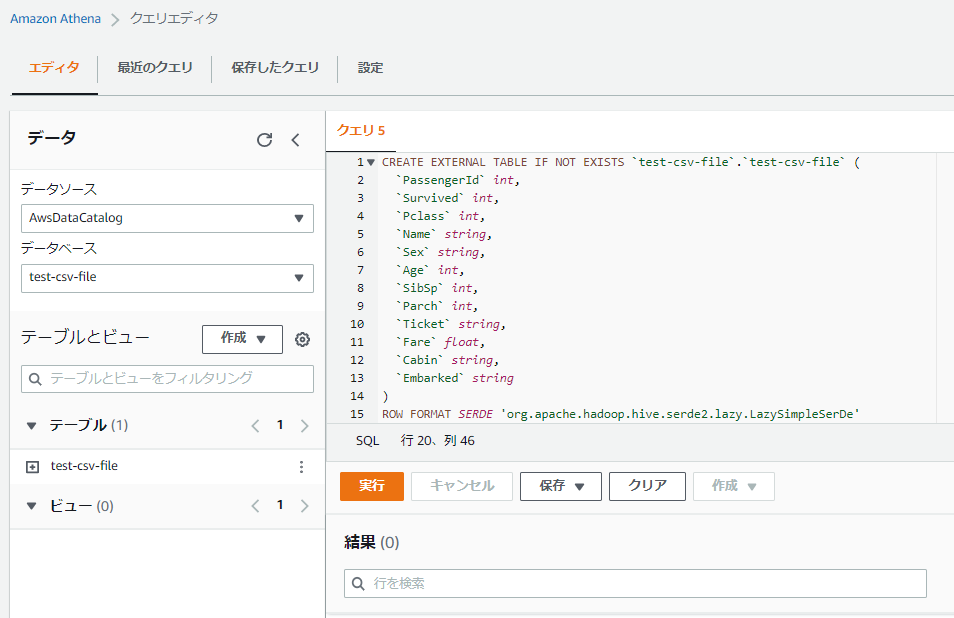
”完了”(クエリは成功しました。)となればテーブルの作成は完了です。

テーブルの内容を確認する
作成したテーブルの設定(3つの点)を右クリックし、「テーブルをプレビュー」をクリックします。
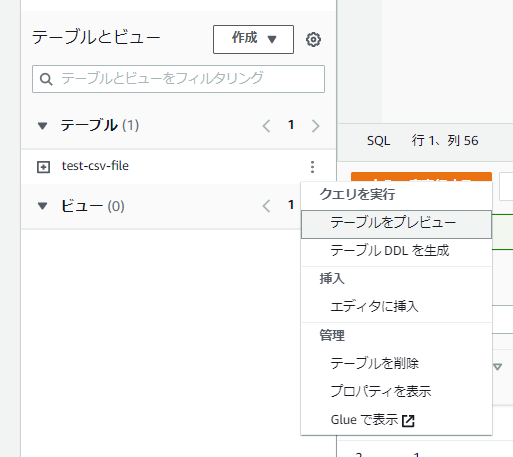
そうすると、クエリが自動作成されます。
SELECT * FROM "test-csv-file"."test-csv-file";「結果」にクエリー結果が表示されます。
No responses yet